
- Tips
2025.10.28
更新日:
2025.07.22
全2回 データの価値創出に向けて——新たなデータマネジメント手法「DataOps」 《連載:第2回》 データマネジメントを効率化・高度化する「DataOps」とは?

大量かつ多様なデータをビジネスに有効活用するためには、データマネジメントの取り組みが重要です。今回は、そのデータマネジメントを高度化し、データ処理の俊敏性と柔軟性を飛躍的に向上させる「DataOps(データオプス)」の基礎知識を紹介します。
DataOpsの3つの特徴
DataOpsには厳密な定義は存在しませんが、IPA(独立行政法人 情報処理推進機構)のDataOpsに関する資料では、次のように説明されています。
「技術のみならず⼈やプロセスの変⾰に取組み、膨⼤な数のデータソースから作成される⾼品質なデータを、データの消費者(引用者注:利用者)に向けて俊敏にかつ継続的に配信するためのデータマネジメント⼿法」
※出典:データマネジメントの⾼度化に対応するためのDataOpsの導⼊ 俊敏で柔軟なデータ処理を可能にす新しいデータマネジメント⼿法|独立行政法人 情報処理推進機構
DataOps(データオプス)は、Data(データ)とOperations(運用)を組み合わせた造語です。これは、システム開発における「DevOps(デブオプス)」、すなわちDevelopment(開発)とOperations(運用)を組み合わせた手法をデータ管理に応用したことに由来しています。実際にDataOpsとDevOpsは、対象とする領域は異なるものの、似たアプローチを採用しています。
例えばDevOpsでは、ニーズや環境の変化に迅速かつ柔軟に対応するため、開発チームと運用チームの密接な連携を重視します。DataOpsでも同様に、データを利用するチーム(例:業務部門)と、データを管理するチーム(例:IT部門)が緊密に連携し、データの正確性や鮮度の継続的な向上・改善を図ります。
また、DevOpsでは、コード変更時のテストや本番環境へのリリースを自動化する「継続的デリバリー(CD)」というアプローチを採用していますが、DataOpsでも、常に新しいデータを処理するデータパイプライン(データを収集し、分析に適した状態に整える仕組みやプロセス)を実現するために、継続的デリバリーを実施します。
もう一点、両者に共通するのが継続的な改善の取り組みです。DataOpsでは、そのためにオブザーバビリティ(可観測性)の確保が重視され、データや処理プロセスの状況を定量的に把握・可視化することで、データの品質やデリバリーに影響を及ぼす問題点を早期に特定し、改善サイクルを迅速に回すことが求められます。
このように、「部門横断的な協働」「自動化」「継続的な改善」というDevOps由来の3つアプローチを重視する点が、従来のデータマネジメントにはないDataOpsの大きな特徴です。
DataOpsで活用されるツール
企業によってベストプラクティスは異なりますが、DataOpsの実現に向けて活用されている基本的なデータマネジメントツールを紹介します。
データの処理プロセス全体において、とりわけ多くの時間と労力を要するのが、データを分析に適した形に整形するプロセスです。いわゆる前処理にあたるこの工程を自動化するツールを活用することで、データ作成者の業務負担を軽減し、データマネジメントの効率化を実現することができます。
・データプリパレーションツール
従来の整形処理と異なり、プログラミング不要で、GUI (グラフィカルユーザーインターフェイス)を用いた視覚的な操作でデータの整形ができるツールです。専門的な知識・スキルのないユーザーでも、簡単にデータの確認や整形をおこなえるのが特長です。複雑な処理が必要なデータに対して、AIや機械学習を活用して欠損値や異常値を自動で検知・補完できるツールも登場しています。
・仮想統合ツール
複数のシステムに分散しているデータを、その属性や特性を示すメタデータを活⽤し、仮想的に再現・統合するツールです。仮想化の特徴は、従来のようなデータの物理的な移動やコピーが不要になり、単一の仮想データレイヤーを通して、多様なデータに一元的かつリアルタイムでデータにアクセスできること。GUI操作で整形処理のシミュレーションをおこない、それを基に物理的な統合データを作成できるツールも登場しており、データソースの追加や新たなデータ統合の作成を柔軟におこなうことも可能です。通常、メタデータは「データカタログ」と呼ばれるツールで一元管理するのが一般的です。
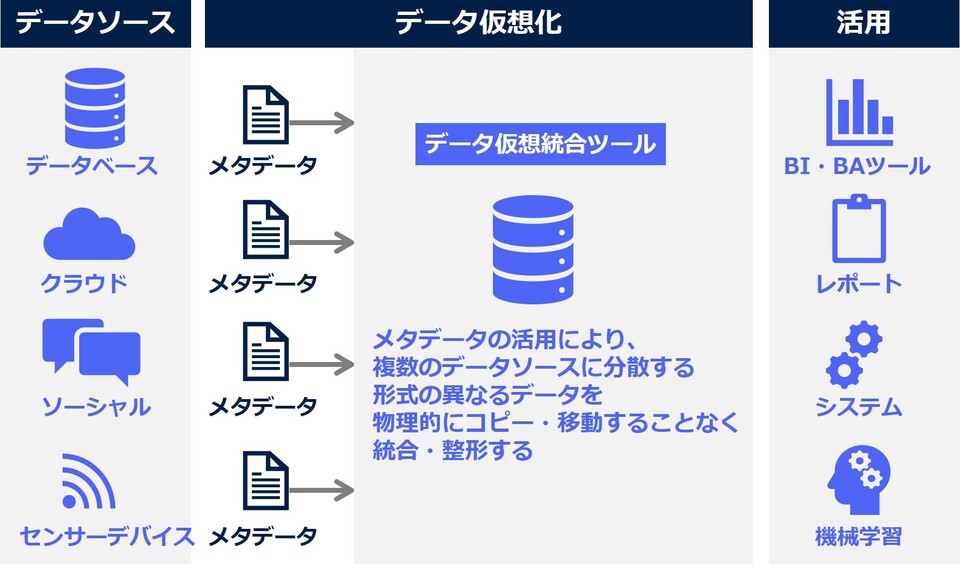
メタデータを活用したデータ仮想化の流れ(イメージ)
・ETL自動化ツール
データの抽出(Extract)、変換(Transform)、格納(Load)という一連のプロセスを自動で実行するツールです。AI・機械学習などによって抽出元のデータ構造を自動分析し、格納先での蓄積に最適な構造へと変換処理をおこないます。人の手による作業を極限まで減らすツールとして期待されていますが、現状、変換処理の自動化については特定のデータソースやロード先に限られるなど、まだまだ限定的です。
・データマネジメントプロセス統合管理ツール
先述のデータプリパレーションツールや、収集したデータを生の状態で保管するデータレイク、分析用に変換された整形データを保管するデータウェアハウスなど、データ処理にかかわるシステムを統合管理するツールも活用されています。統合管理ツールを導入することで、以下のようなメリットを得ることができます。
- プロセス間でのデータの受け渡しを自動化し、デリバリーの時間を短縮できる
- 新しいデータソースからのデータ抽出や保存先の変更など、データ処理フローの管理運⽤をシームレスにおこなえる
- データデリバリーの⼀連のプロセスを俯瞰的に観測し、エラーやボトルネックの要因を特定することができる
データウェアハウスとデータレイクについては↓の記事で詳しく解説しています。
「データウェアハウス」と「データレイク」の違いとそれぞれの特徴|SmartStage
ここまで紹介したデータ処理プロセスの自動化や統合を支援するツールに加えて、データ分析を効率化するツールも活用されています。
・セルフサービスBI
従来のBIツールよりも操作が簡単で、ドラッグ&ドロップなどの直感的な操作や、必要な項目を選択していくだけで、データの可視化や抽出、グラフ作成、レポート作成などが可能です。専門知識を持たない業務部門のユーザーでもデータ分析をおこなうことができるようになるので、よりスピーディーに現場やビジネスのニーズに即した分析を実現することができます。
参照:データマネジメントの⾼度化に対応するためのDataOpsの導⼊ 俊敏で柔軟なデータ処理を可能にする新しいデータマネジメント⼿法|独立行政法人 情報処理推進機構(IPA)
参照:DX白書 第5部DX実現に向けたITシステム開発手法と技術|独立行政法人 情報処理推進機構(IPA)
生成AI時代の新たな役割
今回はDataOpsに関する基礎知識を紹介しましたが、近年、GenAIOpsは新たな展開を見せており、データ品質が出力の成果に大きく影響する生成AIにおいて、AIモデルの開発・運用の最適化を目指す「GenAIOps(Generative AI Ops)」というアプローチの中核を担う役割としても注目が高まっています。また、生成AIを活用したDataOpsプロセスの高度化も広がっていくはずです。
DataOpsは、データマネジメントを効率化・高度化することにより、自社のデータを事業に直接貢献する資産として、その価値を最大化することを目指す取り組みです。ツールや技術の導入だけでなく、体制面の変革など、求められる取り組みは多岐にわたりますが、ビジネスに資する組織への変革を目指すIT部門にとって、決して無視できない、積極的に検討すべきアプローチと言えるでしょう。

