
- IT統制
- Tips
2024.04.03
更新日:
2023.06.13
全2回 データ活用手法の定番とトレンドを知る ~「データウェアハウス」「データレイク」「データファブリック」~ 《連載:第1回》 「データウェアハウス」と「データレイク」の違いとそれぞれの特徴

企業の課題解決や価値創出の手段として、データの重要性が急速に高まっています。その背景にあるのは、IoTやAI(人工知能)を含めたデジタル技術の進展。とりわけ、以前とは比較にならないほど大量かつ多種多様なデータを取得できるようになったことが大きな要因と言われています。
とはいえ、当然ながらデータはただ集めるだけでは価値を生みません。今回は収集したデータの利活用に役立つ管理・分析プラットフォームやアーキテクチャについて、定番から最新トレンドまで紹介します。
様々なソースからデータを蓄積する“倉庫”
企業のデータ管理・分析基盤として、1990年代から活用されてきたのがデータウェアハウス(Data Ware House、DHW)です。直訳するとデータの“倉庫”。複数のシステムやツールがそれぞれ独自の体系で所有しているデータを“時系列”で一元管理することが大きな特徴です。通常のデータベースとは異なり、過去のデータが削除・上書きされることもありません。
ただし、データウェアハウスは扱えるデータの種類が決められています。それは、コンピュータが処理しやすい〈構造化データ〉。構造化データとは、Excelのように「列」や「行」を用いて表形式で整理されたデータ形式を指し、RDBMS(リレーショナルデータベース管理システム)やERP、SCM、CRMなどの基幹業務系システムで扱うデータやPOSデータなどが該当します。また、それぞれのデータをデータウェアハウスに格納する際は、利活用(分析、レポーティングなど)しやすいように加工・整形して、一定の表記や形式に統合する必要があります。
データウェアハウスに集約したデータは、主に目的意思決定に用いられています。そのため、下図のようにBI(ビジネス・インテリジェンス)などのデータ可視化・分析ツールと組み合わせて使われるのが一般的です。
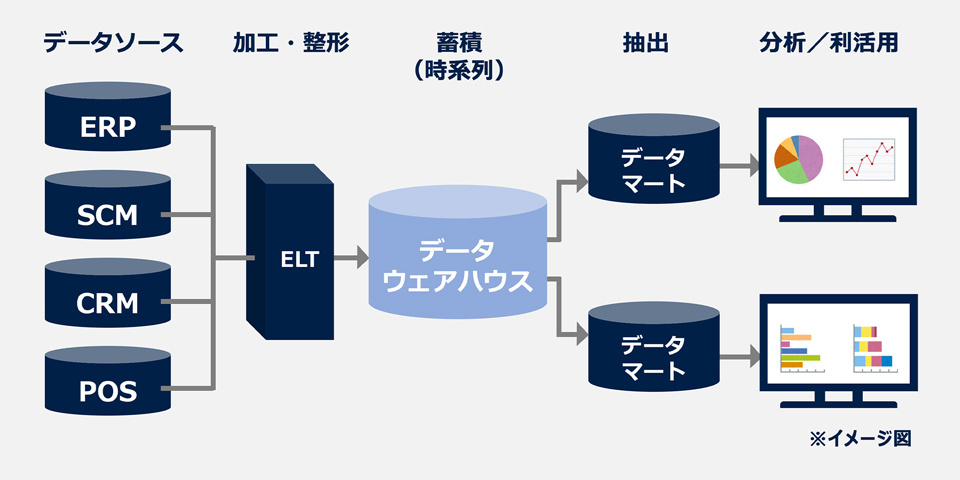
データウェアハウスの活用例
データウェアハウスは通常のデータベースよりも大量のデータを高速で処理することができますが、上述の通り加工・整形のステップが必要なこともあり、一般にリアルタイム分析には不向きとされています。
データウェアハウスの代表的なサービスとしては、Amazonのクラウドサービス『AWS』上に構築できる『AWS Redshift』、Microsoftのクラウドサービス『Azure』上に構築できる『Azure Synapse Analytics』、『Google Cloud』上に構築できる『BigQuery』などのクラウド型が知られています。
非構造化データも取得できるデータの“湖”
2000年代に入り、インターネット、スマートフォン、Web2.0技術などが急速に普及。“ビッグデータ”という言葉にも象徴されるように、流通するデータの量も種類も飛躍的に増大しました。そうした流れの中、2010年頃に登場したのがデータレイクです。
データレイク(Data Lake)の大きな特徴は、データウェアハウスとは異なり、〈構造化データ〉だけでなく〈非構造化データ〉も一元的に管理できることです。非構造化データとは、Excelのような表形式では表せない=明確に構造やフォーマットが定められていないデータのこと。具体的には以下のようなデータを指します。
- テキストデータ(Office文書やメール、SNSの投稿など)
- 画像、動画、音声データ
- IoT機器からのセンサーデータ
- 気象情報などのオープンデータやGPS(全地球測位システム)などの外部データ
- XML/JASON形式の半構造化データ …など
データレイクを直訳すると“データの湖”ですが、業務システムやWebサイト、モバイルアプリケーション、ソーシャルメディア、IoTデバイスなど、様々なデータソースから流れ込んでくるデータを蓄積する“貯水湖”をイメージすると良いかもしれません。
さらにデータレイクは、データウェアハウスのように活用目的に合わせてデータを加工・整形する前処理の必要がなく、“生”のデータ(ローデータ)を未加工あるいは最低限の加工で、ほぼリアルタイムで取得・保存することができます。言い換えると、「とりあえず様々なデータを収集しておいて、後から用途を決める」というやり方が可能ということです。こうした特性は、顧客ニーズや市場の変化に合わせて柔軟な対応が求められる昨今の状況を考えると、大きなメリットと言えるでしょう。
とはいえ、データレイクは必ずしもデータウェアハウスを置き換えるものではありません。データレイクは市場分析のような大規模データのリアルタイム分析やAIによる予測分析、機械学習などの高度な分析に使われていますが、下図のようにBIツールなどによるデータの可視化・分析を目的にデータウェアハウスと併用されることも一般的です。
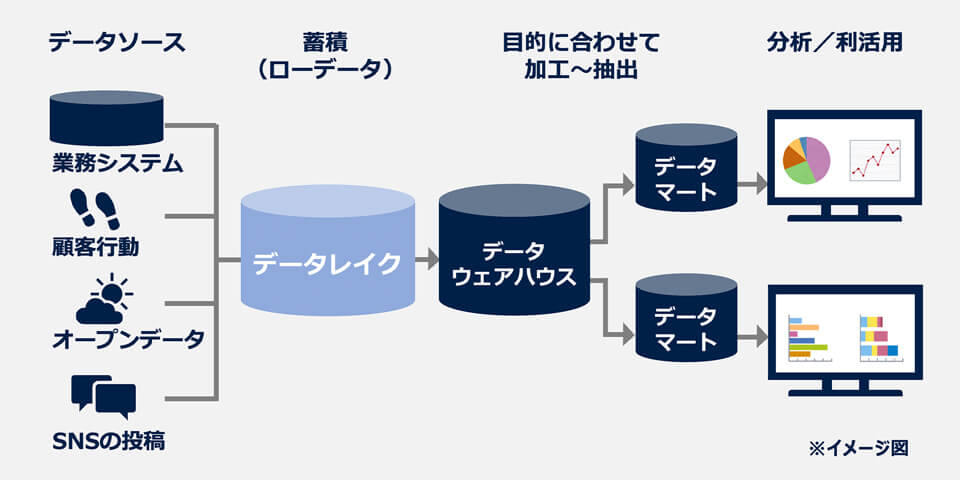
データレイクの活用例
一方、データレイクを活用する上で注意すべき点は、多種多様なネイティブデータが保存されるので、どこに何があるかわからない状態=“データスワンプ(データの沼)”化を防ぐこと。対策としては、データにメタデータ(ファイル名や型など)を付与して検索しやすいように分類する〈データカタログ〉の作成が挙げられます。
なお、データレイクのサービスでは、Amazonの『AWS』上に構築できる『Amazon Simple Storage Service (S3)』や、Microsoftの『Azure』上に構築できる『Azure Data Lake Storage Gen2』などのクラウドストレージサービスが有名です。
次回は、DX時代の新たなデータ利活用のアプローチとして注目を集めている〈データファブリック〉について紹介します。

