
- システム運用
2023.06.01
更新日:
2023.02.14
全2回 運用保守からDXまで――IT部門が押さえておきたい評価指標(KPI)と評価手法 《連載:第1回》 システム評価とインシデント管理に関わる指標

IT部門が定量的な評価指標やKPI(重要業績評価指標)を活用するメリットは、システムやサービスの品質、業務の進捗・達成度合いなど、様々な状況や変化を“可視化”できること。それらを可視化することによって、組織内で課題の共有が容易になり、改善に向けたアクションも明確化しやすくなります。
今回はシステムの運用保守からDXに関するものまで、IT部門が知っておきたい評価指標を活用手法や算出方法などと併せて紹介します。
システムの性能に関する評価指標
〈レスポンスタイム〉
日本語では応答時間と呼ばれています。システムのパフォーマンスを測る上で基本となる指標で、システムに実行指示が与えられて(入力処理が完了)から、最初の応答が返ってくる(出力処理が開始される)までの時間を意味します。
〈ターンアラウンドタイム〉
システムの処理速度を示す指標です。入力処理が発生してから出力処理が終了するまでにかかる総時間を指します。レスポンスタイムとの違いがわかりづらいかもしれませんが、1つのジョブにおけるレスポンスタイムとターンアラウンドタイムの関係性を簡略化すると下図のようになります。
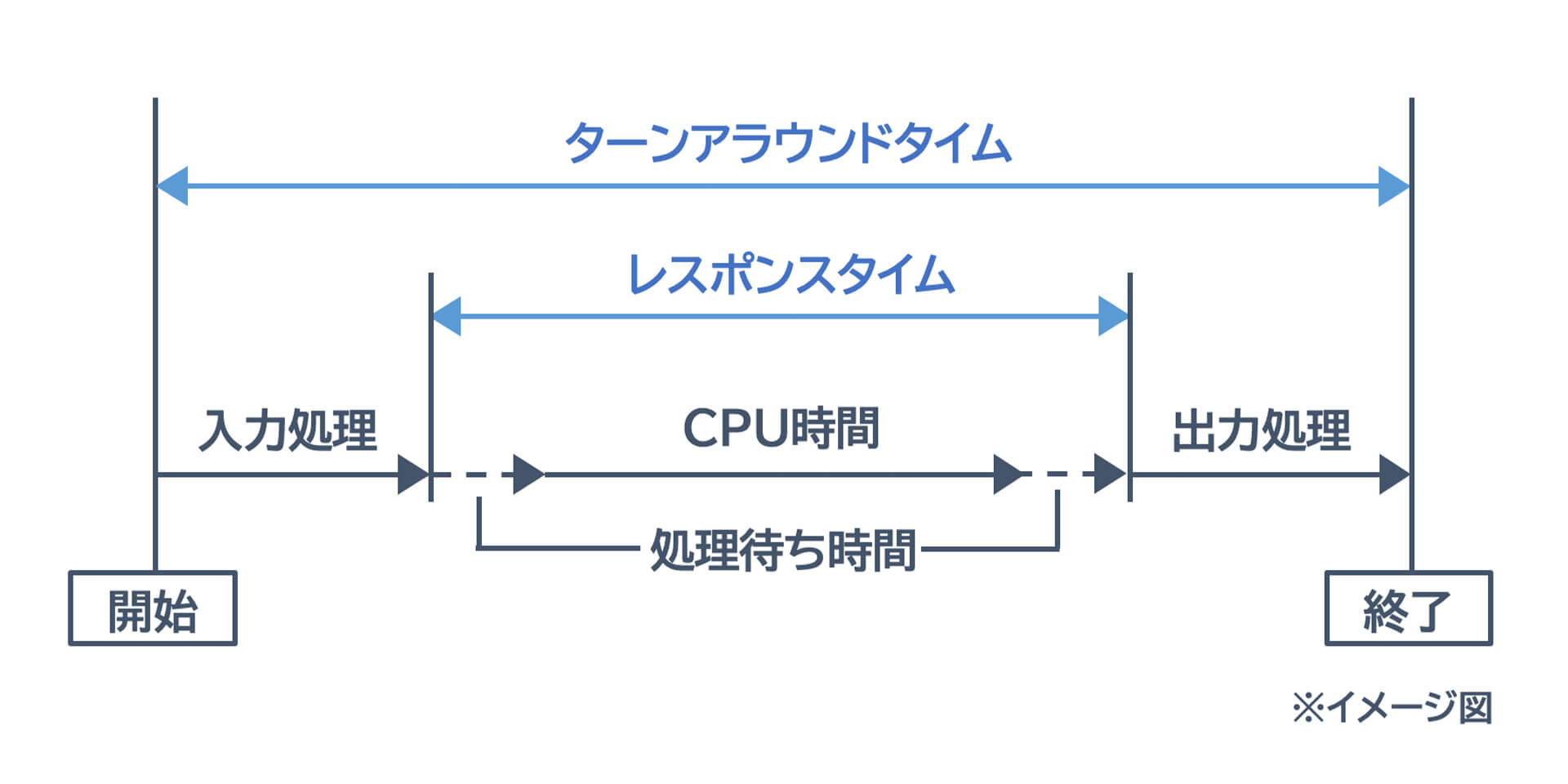
〈スループット〉
システムの処理能力を示す指標です。「トランザクション数/秒または分」といった形で、システムが単位時間当たりに処理できるジョブやトランザクションなどの件数やデータ量を表します。スループットの値が高ければレスポンスタイムも短くなるように思えるかもしれませんが、必ずしもそうなる訳ではありません。
〈ベンチマークテスト〉
上記の性能を測定するためにおこなうのがベンチマークテストです。通常、システムの使用目的にマッチした標準的なテスト用プログラムを用いて測定します。ベンチマークは“基準”や“水準点”を意味する言葉で、テストに用いられる代表的なベンチマークがSPECとTPCです。
・SPEC
国際的な非営利団体SPEC(システム性能評価協会)が策定した、システムの性能を評価するベンチマークです。整数演算性能と浮動小数点演算性能を測る「SPEC CPU」シリーズや、ファイルサーバの性能を計測する「SPECsfs」シリーズなどの種類があります。
・TPC
非営利団体TPC(トランザクション処理性能評議会)が策定した、システムのオンライントランザクション処理(ATMにおける入出金処理など、関連する複数の処理を同時に実行するデータ処理の一種)の性能を評価するベンチマークです。
システムの信頼性に関する評価指標
- 「Reliability」(信頼性:故障しにくい能力)
- 「Availability」(可用性:継続して稼働できる能力、使いたいときに使える)
- 「Serviceability」(保守性:障害が発生した際に迅速に復旧できる能力)
- 「Integrity」(保全性:データが矛盾を起こさずに一貫性を保っていること)
- 「Security」(安全性:機密性が高く、不正アクセスがなされにくいこと)
それぞれの頭文字を取って、ひとまとめに「RASIS(ラシスまたはレイシス)」とも呼ばれています。中でも重要とされているのが1~3つ目の「RAS(ラス)」。いずれも以下の通り、数値的な指標を用いて評価します。
〈MTBF〉(Mean Time Between Failure:平均故障間隔)
システムのReliability(信頼性)を示す指標。システムが稼働を開始してから(=故障が回復してから)次に故障するまでどのくらいの時間稼働できるかを表します。MTBFを長くするためのポイントは、予防保守によって障害発生リスクを下げること。数値は次の計算式で求められます。

〈稼働率〉
システムのAvailability(可用性)を示す指標。ある期間内にシステムが正常に稼動している時間(故障や保守によって停止している時間を除く)の割合を表します。算出方法は下記の通りです。

〈MTTR〉(平均修復時間:Mean Time To Repair)
システムのServiceability(保守性)を示す指標。故障が発生したときに、復旧に要する平均時間を表します。値は総故障時間/故障件数で算出します。

なおMTTRは、DevOps(開発担当者と運用担当者が連携して協力する開発手法)においては、平均復旧時間(Mean Time To Recovery)として指標に用いられています。
インシデント管理のKPI
どれほど高性能・高信頼のシステムでも、想定外のインシデント発生は避けられません。インシデント管理の目的は、そうした際にシステムを速やかに復旧させてビジネスへの影響を最小限に抑えること。一般的には以下の項目がKPIとして使われています。
- 重大なインシデントの数・割合
- SLA(サービス品質保証)で定められた目標対応時間内に対応が完了したインシデントの割合
- MTTR(上述の「システムの信頼性に関する評価指標」参照)
- サービスデスクで解決された割合(初回の対応で解決した割合) など
中でも、インシデントを迅速に解決する上で重要な指標が「サービスデスクで解決された割合」です。サービスデスクだけでクローズできれば、他のプロセス(システムの変更・リリース)による対応が不要になるため、解決までの時間が短くなるからです。
後半の記事では、DX(デジタルトランスフォーメーション)のKPIなど、より経営やビジネスに直結する指標を紹介します。

